内容简述:JDBC概述、封装JDBCUtils工具类、Statement、PreparedStatement、批处理、事务、返回自增主键、JDBC操作分页。
一、JDBC概述、怎样使用JDBC、初步封装
JDBC概述
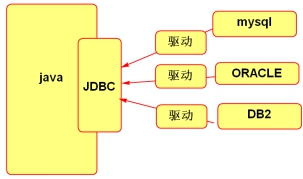
JDBC是什么
JDBC是一套sun公司定义的接口,是一套标准,规定了统一的数据库访问方法
各个数据库厂商实现这套标准,让java程序能操作数据库
为什么使用JDBC
- jdbc的好处:我们只学习一套接口的使用和操作,就可以访问任何数据库了。
怎么使用JDBC
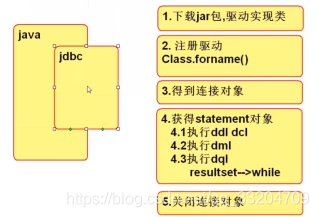
下载驱动,mysql驱动,去Maven库搜索MySQL connector下载即可;
把驱动加载到java环境中,注册驱动;
1
2// 注册驱动
Class.forName("com.mysql.jdbc.Driver");获得连接对象 Connection
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18public static void main(String[] args) throws Exception {
//1.注册驱动
Class.forName("com.mysql.jdbc.Driver");
//2.获得Connection对象
//url jdbc:mysql://数据库IP:端口号/库名
//username 数据库用户名
//password 数据库密码
Connection conn=DriverManager.getConnection(
"jdbc:mysql://localhost:3306/demo1",
"root", "root");
//验证是否连接成功
System.out.println(conn);
//证明接口实现类来自驱动
System.out.println(conn.getClass());
}
- 补充:
- 如果使用mysql版本为6.0以上的jar包,url 中要添加时区指定。
- “jdbc:mysql://localhost:3306/demo1?serverTimezone=Asia/Shanghai”——-地方时区;
- “jdbc:mysql://localhost:3306/demo1?serverTimezone=UTC”———国际的标准时区。
连接上数据库后,要执行sql语句,使用Statement对象执行sql语句。
4.1. 执行DDL
1
2
3
4
5
6String ddl="create table demo_2(id int,name varchar(20))";
// true 代表有返回结果集
// false 代表没有返回结果集
boolean flag=sta.execute(ddl);
System.out.println(flag);4.2. 执行DML
1
2
3// 插入操作 DML
String dml="insert into demo_2 values(1,'hanmeimei')";
sta.executeUpdate(dml);4.3. 执行DQL,处理结果集
1
2
3
4
5
6
7
8
9//查询
String dql="select 'hello' as a from dual";
//使用execute(dql)执行查询语句
ResultSet rs=sta.executeQuery(dql);
while(rs.next()){
String str=rs.getString("a");
System.out.println(str);
}关闭连接对象
1
conn.close();
ResultSet 游标
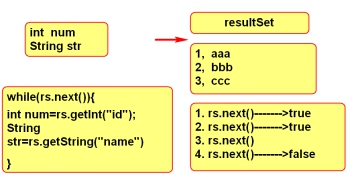
- ResultSet对象,使用游标控制数据 ;
- 当执行查询语句的时候,resultSet对象用于封装查询结果方法;
- Boolean rs.next()
- 让结果集中的游标往下移动一行;
- 判断该行是否有数据!有的话,返回true,没有就返回false。
- rs.getXXX() 有很多种,分别对应数据库中不同的数据类型;
- 数据库类型 get方法
- char/varchar getString()
- int getInt()
- bigint getLong()
- float/double getFloat()/getDouble()
- datetime/timestamp getDate()
初步封装
java面向对象的思想,让我们获得连接对象的代码可以重用;
创建一个工具类 DBUtils,封装获取连接对象的静态方法:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36public class DBUtils {
/**
* 1.创建静态方法getConnection,返回值为Connection对象
*/
public static Connection getConnection() throws Exception{
// 1.1把4个字符串拆分出来
String driver="com.mysql.jdbc.Driver";
String url="jdbc:mysql://localhost:3306/demo1";
String userName="root";
String password="root";
// 1.2注册驱动
Class.forName(driver);
// 1.3获取连接对象
Connection conn=DriverManager.getConnection(url, userName, password);
return conn;
}
public static void main(String[] args) throws Exception {
// 调用封装的getConnection方法获得连接对象
Connection conn=DBUtils.getConnection();
String sql="select * from demo_2";
// 获取statement对象
Statement sta=conn.createStatement();
ResultSet rs=sta.executeQuery(sql);
while(rs.next()){
int id=rs.getInt(1);
String str=rs.getString(2);
System.out.println(id);
System.out.println(str);
}
conn.close();
}
}
课堂练习
完成DBUtils的封装,并且测试成功
思考尝试一下,封装conn.close()
封装进阶
JDBC可以操作所有的数据库;
如果我们现在想要更换数据,或者更换用户/密码/库,需要进入代码去更改;
把4个字符串driver,url,username,password,放到一个配置文件中,以便后期维护。
课堂练习
- 完全熟悉jdbc操作数据的库基本流程 (Connection对象,Statement对象,Properties对象);
- 完成进阶封装的代码操作;
- 对emp表,进行3次增删改查操作。
二、连接池技术、优化Statement对象(使用PreparedStatement)
连接池
- DBCP database connection pool—apache
- 缓存中存储了连接对象,可以重用连接对象的技术。
为什么使用连接池
- 重用了数据库连接对象,提高了连接效率:
在缓存(内存)中保存了一些connection对象,使用的时候拿出来用,用完了归还给缓存
从内存获取和归还connection对象的效率,要远远高于创建和销毁connection对象的效率
保护数据库连接数量,避免连接过载;
使用一个数据库的管理员,管理员对数据库连接做管理,导入包,并直接使用。

课堂练习

1 | public static void main(String[] args) { |
封装连接池,完成查询表内容

多线程演示连接池的等待效果

数据库执行计划
目的:优化Statement对象,重用执行计划。
sql语句数据库是不认识的,需要进行编译,编译后的结果叫做执行计划。
执行一条sql语句,就产生一个执行计划。
同样的sql语句,哪怕一丁点的不一样(比如数据不一样,大小写不一样,空格不一样等),就会重新产生一个执行计划。
因此,我们要优化statement对象,重用执行计划:
- 优化方法—–>使用PreparedStatement
- Statement:一般用于执行不发生改变的sql语句(比如DDL,DCL,TCL等)
- PreparedStatement:一般用于执行发生改变的sql语句(比如DML,DQL等)
- 优化方法—–>使用PreparedStatement
示例:
1 | //?是占位符,把可变数据的位置占住 |
PreparedStatement的另一个功能是:可以防止sql注入。
注意:PreparedStatement不需要单引号修饰问号,但是Statement需要。
三、批量处理、结果集元数据、事务、返回自增主键、JDBC操作分页
批量处理
问题:Connection是一次连接,一次jdbc和数据库的响应叫一次通讯。当执行多条SQL的时候,就需要进行多次连接通讯,效率低。

Statement 解决方案:
- 在jdbc中设置一个缓存区用于积攒sql语句,积攒一定数量之后执行;
- 因为sql语句是DDL语句,所以执行语句不能省,只是节省通讯次数。

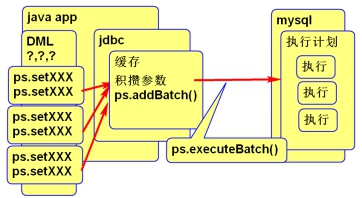
PreparedStatement解决方案:
- 使用批量处理
积攒DDL语句,使用Statement对象
1
2
3
4sta.addBatch(ddl);
sta.executeBatch();
sta.clearBatch();完整方法:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33public static void main(String[] args) {
//准备一批sql语句
String ddl1="create table log1(id int,msg varchar(20))";
String ddl2="create table log3(id int,msg varchar(20))";
String ddl3="create table log4(id int,msg varchar(20))";
String ddl4="create table log5(id int,msg varchar(20))";
String ddl5="create table log2(id int,msg varchar(20))";
Connection conn=null;
try {
conn=DBUtils1.getConnection();
Statement sta=conn.createStatement();
//把一批sql语句添加到缓存中
sta.addBatch(ddl1);
sta.addBatch(ddl2);
sta.addBatch(ddl3);
sta.addBatch(ddl4);
sta.addBatch(ddl5);
//执行一批SQL语句
int[] arr=sta.executeBatch();
//返回值有3种
//1.>=0 代表成功
//2.代表成功-2
//oracle对executeBatch()并不完全支持,返回-2
//3.代表失败-3
for (int i = 0; i < arr.length; i++) {
System.out.println(arr[i]);
}
} catch (Exception e) {
e.printStackTrace();
}finally{
DBUtils1.closeConnection(conn);
}
}
积攒参数,使用PreparedStatement,重用执行计划。
1
2
3ps.addBatch();
ps.executeBatch();
ps.clearBatch();完整方法:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28public static void main(String[] args) {
// 准备dml语句
String dml = "insert into log1 values(?,?)";
Connection conn = null;
try {
conn=DBUtils1.getConnection();
PreparedStatement ps = conn.prepareStatement(dml);
// 把一批参数添加到ps的缓存中
ps.setInt(1, 1);
ps.setString(2, "1111");
ps.addBatch();
ps.setInt(1, 2);
ps.setString(2, "2222");
ps.addBatch();
ps.setInt(1, 3);
ps.setString(2, "3333");
ps.addBatch();
// 批量执行一批参数
int[] arr = ps.executeBatch();
for (int i = 0; i < arr.length; i++) {
System.out.println(arr[i]);
}
} catch (Exception e) {
e.printStackTrace();
}finally {
DBUtils1.closeConnection(conn);
}
}
结果集元数据
- 就是结果集的相关信息。
- 目的:为了获取结果集中其它的描述信息。

举个栗子:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25public static void main(String[] args) {
Connection conn = null;
try {
conn=DBUtils1.getConnection();
String sql="select * from emp";
Statement sta=conn.createStatement();
ResultSet rs=sta.executeQuery(sql);
// 获取元数据
ResultSetMetaData meta = rs.getMetaData();
// 获取列的数量
int n = meta.getColumnCount();
System.out.println(n);
// 获取列的名称
String name1=meta.getColumnName(1);
String name2=meta.getColumnName(2);
System.out.println(name1+"~"+name2);
for(int i = 1; i <= meta.getColumnCount(); i ++){
System.out.println(meta.getColumnName(i));
}
} catch (Exception e) {
e.printStackTrace();
}finally {
DBUtils1.closeConnection(conn);
}
}
课堂练习
使用sta对象,批量执行DDL语句 5个
1
2
3log6 (id int,msg varchar(20));
sta.addBatch(sql);
sta.executeBatch()使用PreparedStatement对象,批量更新20条数据。
- 注意控制不要让内存溢出。
事务
1 | sql> set autocommit=0; |
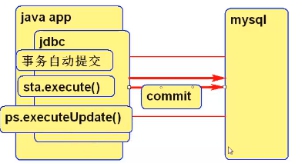
课堂练习
借钱的业务
1
2
3
4create table account1( id int, name varchar(20), money double(7,2) );
insert into account1 values(1,'aaa',10000);
insert into account1 values(2,'bbb',100);
完成转账事务逻辑
提高,把这个逻辑封装成方法
- pay(int from,int to,double money)
- from—>减钱的账户ID
- to—–>加钱的账户id
- money–>转了多少钱
注意:如果是抛异常一定要自己调用回滚,因为我们在关闭连接对象的时候需要恢复自动提交,如果不自己调用回滚的话,缓存中的sql语句在恢复自动提交的时候也会执行。
返回自增主键
问题:在我们的日常开发过程中,数据的主键我们一般是使用数据库自动生成的序列。
那么如何在新增数据库之后获取到该条数据自动生成的主键序列呢?
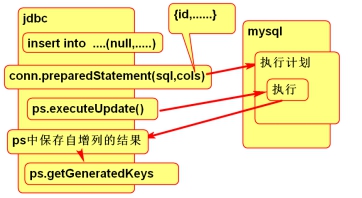

解决方案:
- 1.在建表的时候指定主键序列为自增长,auto_increment;
1 | create table post( |
- 2.java语句:
1 | /** |
JDBC操作分页
- MySQL大表查询必须使用分页
1 | select id from keywords limit 1,5; |
Java 代码:
1 | public static void main(String[] args) { |
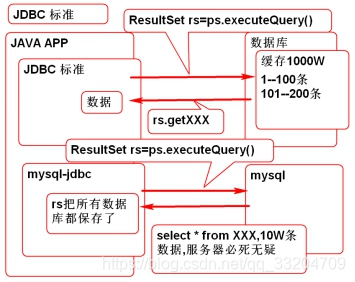
为什么MySQL查询大表必须要分页?
- 官方要求查询结果存在数据库的缓存中,直到rs.getXXX,数据才会传到服务器内存;
- 但是MySQL根标准官方建议不一样,对JDBC查询实现的不好;
- MySQL只要一执行查询,就把结果全部存到服务器内存中了;
- MySQL只要查询大表,必须使用分页;
- 所以mysql的分页操作非常简单,算是一种补救。
注意:查询尽量不要使用select *,查询字段冗余,而且如果表结构变更,系统报错不容易排查原因。


- 本文作者: ACG kaka
- 本文链接: http://acgkaka.github.io/2020/11/11/8Java入门(八)JDBC/
- 版权声明: 文章均为个人整理,如有侵权,请联系删除。